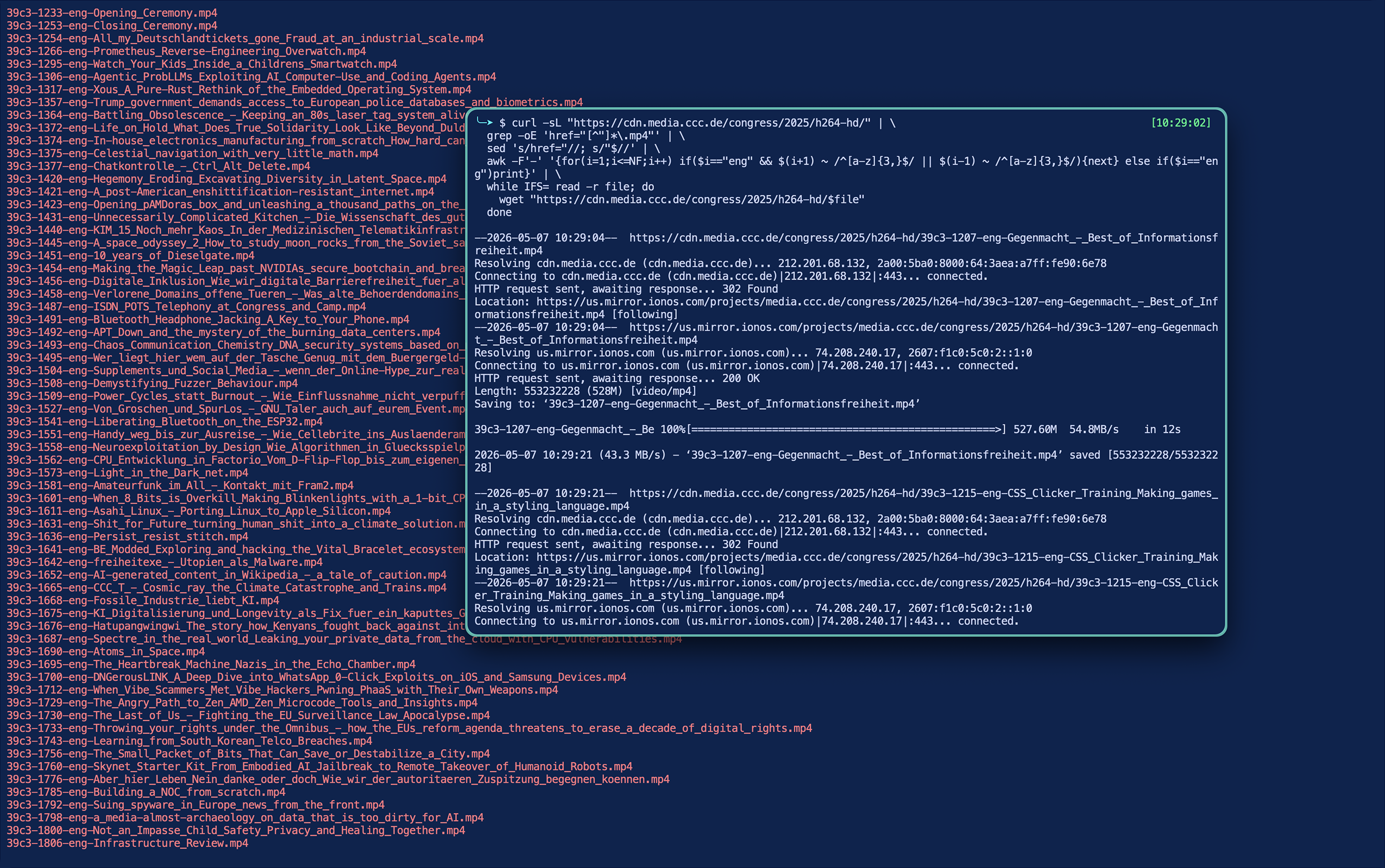
Love love love media.ccc.de by Chaos Computer Club. And I love that all of the files are available via their CDN.

Browsing to the corner of the CDN with 39c3’s videos I decided I wanted to pull down only the English versions.
This is the shell one-liner I wrote to parse the HTML, filter it via awk and looping through to download just the files I was after:
curl -sL "https://cdn.media.ccc.de/congress/2025/h264-hd/" | \
grep -oE 'href="[^"]*\.mp4"' | \
sed 's/href="//; s/"$//' | \
awk -F'-' '{for(i=1;i<=NF;i++) if($i=="eng" && $(i+1) ~ /^[a-z]{3,}$/ || $(i-1) ~ /^[a-z]{3,}$/){next} else if($i=="eng")print}' | \
while IFS= read -r file; do
wget "https://cdn.media.ccc.de/congress/2025/h264-hd/$file"
doneIf that’s not so much your thing, their frontend is nicely accessible as well. https://media.ccc.de/c/39c3
Leave a Reply